
Written by Brett Rakestraw
When I saw the early tests for AI image generation using text prompts, I was both excited and underwhelmed. These early experiments generated very low-res, mainly fuzzy shapes and blobs of color that could be just about anything if you squint hard enough. But, just a few years later, those fuzzy blobs began to take true form.
It was early 2021, when OpenAI’s DALL•E text-to-image generator was announced. OpenAI first made waves with an impressive natural language text generator called GPT-3. That tool generates text so convincing, it’s hard to tell it apart from human-generated content. Case in point, GPT-3 wrote the end of that last sentence for me. The team at OpenAI used a modified version of the GPT model to explore image creation in what would become DALL•E. And, very much like GPT-3, news of DALL•E turned a lot of heads.
The results of some of OpenAI’s prompts, although admittedly cherry-picked, were beyond anything I could’ve imagined to that point. You might’ve seen a group of images depicting an “armchair in the shape of an avocado” that quickly went viral, not just because the images looked like real photos, but because there were dozens of unique avocado shaped chair designs that didn’t even exist in the real world.

The idea of creating convincing images with basic text inputs was quite compelling, especially for those of us whose jobs revolve around constant creative output. Immediate use cases came to mind for storyboarding and scene building. The problem? DALL•E was just a promising case study and wasn’t open for public use.
But in April, OpenAI announced DALL•E 2, and with it, a public beta. For the first time, a large number of people would have the chance to put text-to-image AI to the test. Not to be left behind, Google quickly showcased its own text-to-image AI model called Imogen, although Imogen isn’t yet open to the public.
In June, Midjourney, an independent AI research firm, launched a public beta of their own text-to-image generator. Even Meta dropped some hints about a research project called ‘Make-A-Scene’ that attempts to render more specific scenes based on a combination of text prompts and simple user uploaded sketches.
It seems that AI is finally ready to shake up the design world. But, is that a good thing? Depending on who you ask, these impressive tools are going to either open up new worlds of creativity, or they’re going to steal all the jobs from today’s working artists.
Let’s take a deeper look at the two generators operating in public betas today, DALL•E 2 and Midjourney.
The lowdown
I should note that AI has already made its way into popular design tools like Photoshop. This is often by way of filters to quickly colorize an image or smooth skin on a portrait. But, they have generally been tools that aid an artist or designer in a specific task, as opposed to tools that generate entire scenes with no design skills needed. What we are seeing today, is an entirely new level of visual output.
Let’s start with DALL•E 2 from OpenAI. While its predecessor could interpret a concept like an “avocado shaped chair”, DALL•E 2 can handle more complex inputs like “a bowl of soup that is a portal into another dimension as digital art”. It’s also faster and produces images with 4x the resolution, according to its creators.
When generating images on DALL•E 2, the AI returns 4 options, each with a different take on the request. Currently, all images generated in DALL•E 2 are square at 1024 x 1024 pixels.
Once the images are generated, a user can run a series of variations on a given result with the click of a button. Three variations will be returned, and this process can be repeated indefinitely.
Additionally, DALL•E has an edit feature built in that lets users erase a portion of an image and have the AI replace the missing part. This can be useful when a result is close but it just needs a few tweaks.
Midjourney has a slightly different approach to their controls. It's currently operated through a Discord server. Seemingly an odd choice for a software platform, but David Holz, the founder of Midjourney believes it should be a community tool and a shared experience. Discord makes it feel more like a community, where all of the generated images are public, unless a user pays for the private option.
After entering a prompt in the Midjourney Discord, the AI generates 4 options just like DALL•E. Midjourney lets users generate variations with one click as well. But, Midjourney also lets users 'up-res' any result in two different ways, one with more detail and one with less detail.
By default, Midjourney generates square images at 512 x 512, but final versions can be around 1664 x 1664, making them better for large screens or print. Additionally, Midjourney lets users set any aspect ratio of their choosing, as long as it fits the parameters for overall size.
While both engines are capable of producing some stunning results, the systems were built with somewhat different intentions that become fairly obvious right away. For example, DALL•E excels at photographic results, whereas Midjourney leans heavily into artistic impressions.
The best way to really understand what these tools are capable of is to compare results. So, let’s take a look.
The showdown
To get a baseline, I put a basic prompt into both engines, “Bob Marley, photorealistic”. It’s easy to see that both tools can generate results that look ‘real’. However, neither produced an image that looks like a true photograph of Bob Marley.
 This is on purpose. Neither platform wants to be responsible for deep-fakes, so they’ve taken two different approaches to curb this. DALL•E produced a photo-like image, and they clearly referenced the famous singer. But, they won’t let the AI produce an exact likeness. Instead, we get a random man with dreadlocks who, quite honestly, looks more like Adam Duritz from Counting Crows. You see it now, don’t you?
This is on purpose. Neither platform wants to be responsible for deep-fakes, so they’ve taken two different approaches to curb this. DALL•E produced a photo-like image, and they clearly referenced the famous singer. But, they won’t let the AI produce an exact likeness. Instead, we get a random man with dreadlocks who, quite honestly, looks more like Adam Duritz from Counting Crows. You see it now, don’t you?
On the other side, Midjourney generated something with a much closer likeness to Bob Marley, but it won’t produce something that could be mistaken for a real photo of the deceased musician.
While I find it far more interesting to produce an artistic representation of a real historical figure, I can see issues arising if the wrong image of the wrong person makes its way through the Midjourney engine and into the world. This is one of the many hurdles AI image generation will have to overcome to be viable for long term use.
Keeping with the theme of people, I tried a more complex scene description. This time, prompting the engine to generate “an older man, sitting next to a record player, listening to music with closed eyes, wide shot, photorealistic”.
Both engines, in their current forms, can struggle with faces under certain circumstances. While the last prompt generated realistic faces, the addition of other elements in the scene seems to throw it off a litte.
In the first result from DALL•E 2, the composition was realistic, but the face, among other elements, was distorted. I quickly erased the head and let DALL•E 2 give it another shot. The updated image had a more realistic face, but it was a little small for the body.

The results from Midjourney couldn’t be more different here? Looking closely, the Midjourney images actually have more ‘flaws’, but without any specific prompts, the Midjourney engine created a more cinematic composition and painterly style. This is where Midjourney really excels for idea generation versus production art creation.

This example highlights exactly how the two engines ‘think’ differently from one another. DALL•E 2 aims to output a very specific thing that the user asks for. While Midjourney wants to be more of an “imagination engine” as David Holz has often said in interviews.
With that in mind, I took a look at how well the two engines replicate specific art styles as well as specific artists. I used the prompt "a glass of water on an empty table" for these tests. In the versions on the left, I included the modifier "watercolor". For the second version, I included "Pablo Picasso". The results are quite different from each other, but all of them fit into the framing of my prompts.
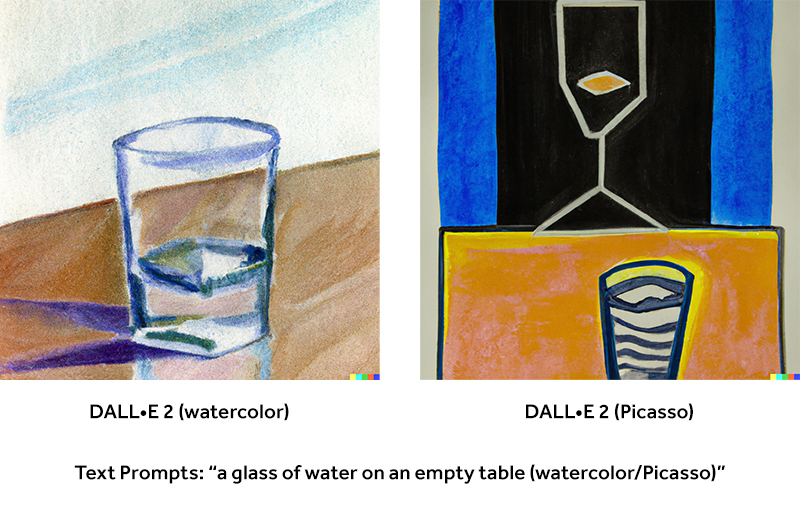
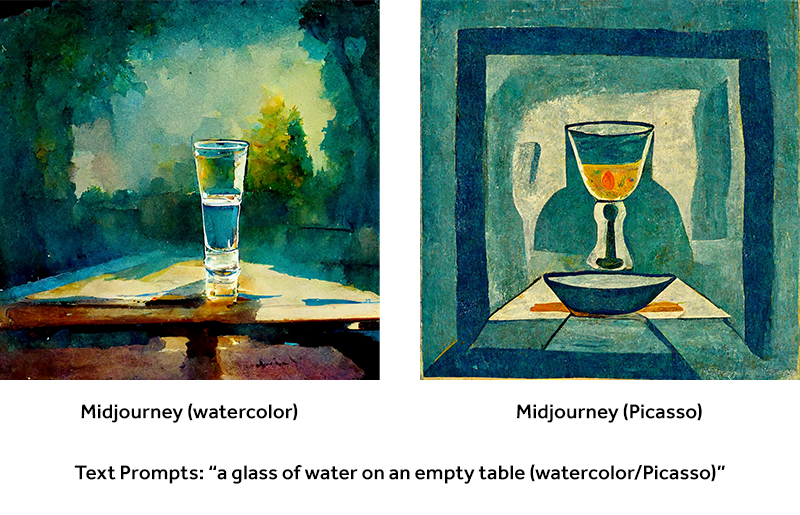
For the final comparison, I wanted to see how the two systems would handle a much more abstract concept. So, I entered the prompt, "what it feels like to be loved." I made a few tweaks to each prompt to best fit the system. For DALL•E, I included the modifier "digital art". This was to avoid getting photographic results of couples. For Midjourney, I set the aspect ratio to 16 x 9.
The results show again that DALL•E interprets concepts the way they are most commonly interpreted, while Midjourney works in more fantastical ways, particularly around feelings and vague concepts.

 Where do we go from here?
Where do we go from here?
Even with all of their current shortcomings, it's clear that both DALL•E 2 and Midjourney have crossed a threshold that was completely unthinkable a few years back. Both systems are improving at breakneck pace. For example, Midjourney has updated their algorithm three times in the past several months, getting significantly more convincing with each iteration.
We already know Google and Meta will be releasing similar tools before long, and I think it's safe to say we'll eventually have dozens if not hundreds of text-to-image AI engines, each with their own specialties and quirks.
But, as the camera threatened painters and the computer threatened traditional artists, AI is just another tool that has the ability to take art and design in new directions.
We have to remember that the AI is trying to represent what we input, and it can serve to spark the imagination, but what the computer doesn’t have is intent, it doesn’t have nuance, and it can't make judgements on context.
The best thing we can do is interact with it, learn what it does well and make up for what it doesn't do well, gain inspiration from its output, and maybe save a little time in the process. But, AI doesn't exist without humans and I don't think AI will replace them either... at least not any time soon.
Topics: creative strategy, future of creativity, visual storytelling